I’m pleased to announce a release of Dask’s distributed scheduler, dask.distributed, version 1.13.0.
conda install dask distributed -c conda-forge
or
pip install dask distributed --upgrade
The last few months have seen a number of important user-facing features:
- Executor is renamed to Client
- Workers can spill excess data to disk when they run out of memory
- The Client.compute and Client.persist methods for dealing with dask
collections (like dask.dataframe or dask.delayed) gain the ability to
restrict sub-components of the computation to different parts of the
cluster with a
workers=keyword argument. - IPython kernels can be deployed on the worker and schedulers for interactive debugging.
- The Bokeh web interface has gained new plots and improve the visual styling of old ones.
Additionally there are beta features in current development. These features are available now, but may change without warning in future versions. Experimentation and feedback by users comfortable with living on the bleeding edge is most welcome:
- Clients can publish named datasets on the scheduler to share between them
- Tasks can launch other tasks
- Workers can restart themselves in new software environments provided by the user
There have also been significant internal changes. Other than increased performance these changes should not be directly apparent.
- The scheduler was refactored to a more state-machine like architecture. Doc page
- Short-lived connections are now managed by a connection pool
- Work stealing has changed and grown more responsive: Doc page
- General resilience improvements
The rest of this post will contain very brief explanations of the topics above. Some of these topics may become blogposts of their own at some point. Until then I encourage people to look at the distributed scheduler’s documentation which is separate from dask’s normal documentation and so may contain new information for some readers (Google Analytics reports about 5-10x the readership on http://dask.readthedocs.org than on http://distributed.readthedocs.org.
Major Changes and Features
Rename Executor to Client
http://distributed.readthedocs.io/en/latest/api.html
The term Executor was originally chosen to coincide with the
concurrent.futures
Executor interface, which is what defines the behavior for the .submit,
.map, .result methods and Future object used as the primary interface.
Unfortunately, this is the same term used by projects like Spark and Mesos for “the low-level thing that executes tasks on each of the workers” causing significant confusion when communicating with other communities or for transitioning users.
In response we rename Executor to a somewhat more generic term, Client to designate its role as the thing users interact with to control their computations.
>>>fromdistributedimportExecutor# Old>>>e=Executor()# Old>>>fromdistributedimportClient# New>>>c=Client()# NewExecutor remains an alias for Client and will continue to be valid for some
time, but there may be some backwards incompatible changes for internal use of
executor= keywords within methods. Newer examples and materials will all use
the term Client.
Workers Spill Excess Data to Disk
http://distributed.readthedocs.io/en/latest/worker.html#spill-excess-data-to-disk
When workers get close to running out of memory they can send excess data to
disk. This is not on by default and instead requires adding the
--memory-limit=auto option to dask-worker.
dask-worker scheduler:8786 # Old
dask-worker scheduler:8786 --memory-limit=auto # New
This will eventually become the default (and is now when using LocalCluster) but we’d like to see how things progress and phase it in slowly.
Generally this feature should improve robustness and allow the solution of larger problems on smaller clusters, although with a performance cost. Dask’s policies to reduce memory use through clever scheduling remain in place, so in the common case you should never need this feature, but it’s nice to have as a failsafe.
Enable restriction of valid workers for compute and persist methods
http://distributed.readthedocs.io/en/latest/locality.html#user-control
Expert users of the distributed scheduler will be aware of the ability to restrict certain tasks to run only on certain computers. This tends to be useful when dealing with GPUs or with special databases or instruments only available on some machines.
Previously this option was available only on the submit, map, and scatter
methods, forcing people to use the more immedate interface. Now the dask
collection interface functions compute and persist support this keyword as
well.
IPython Integration
http://distributed.readthedocs.io/en/latest/ipython.html
You can start IPython kernels on the workers or scheduler and then access them directly using either IPython magics or the QTConsole. This tends to be valuable when things go wrong and you want to interactively debug on the worker nodes themselves.
Start IPython on the Scheduler
>>>client.start_ipython_scheduler()# Start IPython kernel on the scheduler>>>%schedulerscheduler.processing# Use IPython magics to inspect scheduler{'127.0.0.1:3595':['inc-1','inc-2'],'127.0.0.1:53589':['inc-2','add-5']}Start IPython on the Workers
>>>info=e.start_ipython_workers()# Start IPython kernels on all workers>>>list(info)['127.0.0.1:4595','127.0.0.1:53589']>>>%remoteinfo['127.0.0.1:3595']worker.active# Use IPython magics{'inc-1','inc-2'}Bokeh Interface
http://distributed.readthedocs.io/en/latest/web.html
The Bokeh web interface to the cluster continues to evolve both by improving existing plots and by adding new plots and new pages.
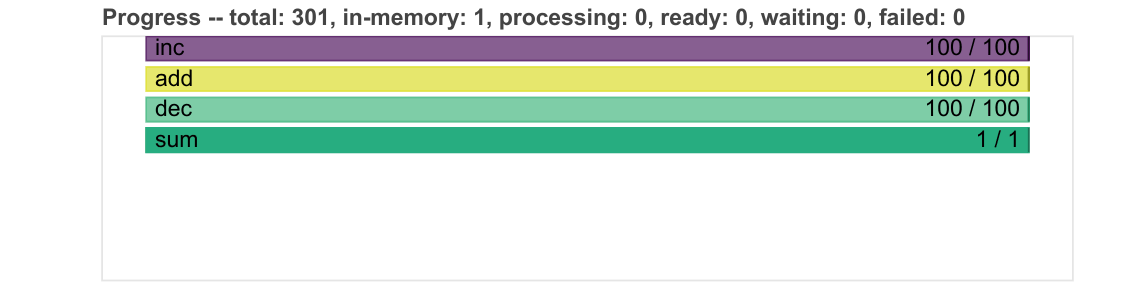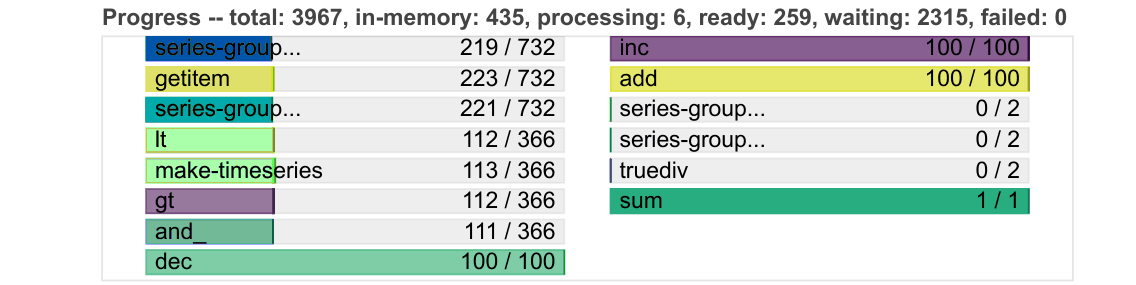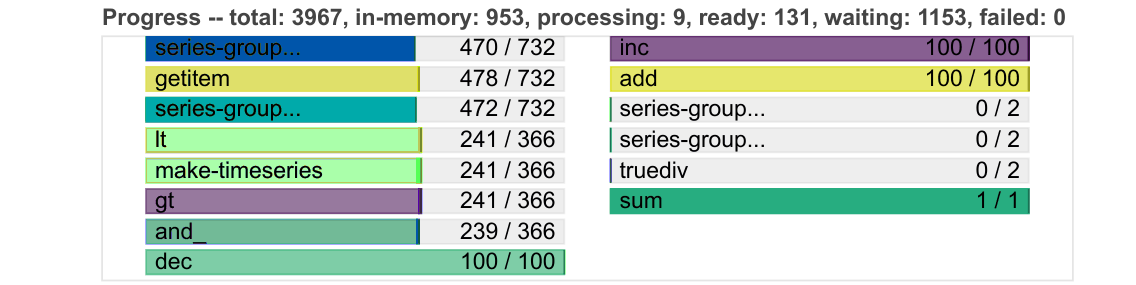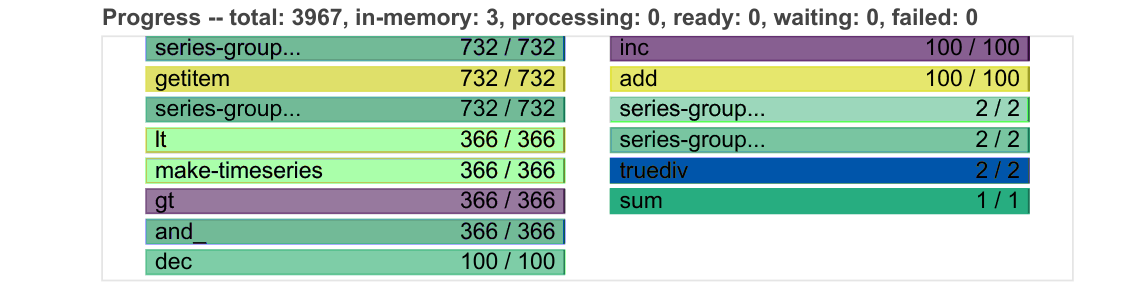
For example the progress bars have become more compact and shrink down dynamically to respond to addiional bars.
And we’ve added in extra tables and plots to monitor workers, such as their memory use and current backlog of tasks.
Experimental Features
The features described below are experimental and may change without warning. Please do not depend on them in stable code.
Publish Datasets
http://distributed.readthedocs.io/en/latest/publish.html
You can now save collections on the scheduler, allowing you to come back to the same computations later or allow collaborators to see and work off of your results. This can be useful in the following cases:
- There is a dataset from which you frequently base all computations, and you want that dataset always in memory and easy to access without having to recompute it each time you start work, even if you disconnect.
- You want to send results to a colleague working on the same Dask cluster and have them get immediate access to your computations without having to send them a script and without them having to repeat the work on the cluster.
Example: Client One
fromdask.distributedimportClientclient=Client('scheduler-address:8786')importdask.dataframeasdddf=dd.read_csv('s3://my-bucket/*.csv')df2=df[df.balance<0]df2=client.persist(df2)>>>df2.head()namebalance0Alice-1001Bob-2002Charlie-3003Dennis-4004Edith-500client.publish_dataset(accounts=df2)Example: Client Two
>>>fromdask.distributedimportClient>>>client=Client('scheduler-address:8786')>>>client.list_datasets()['accounts']>>>df=client.get_dataset('accounts')>>>df.head()namebalance0Alice-1001Bob-2002Charlie-3003Dennis-4004Edith-500Launch Tasks from tasks
http://distributed.readthedocs.io/en/latest/task-launch.html
You can now submit tasks to the cluster that themselves submit more tasks. This allows the submission of highly dynamic workloads that can shape themselves depending on future computed values without ever checking back in with the original client.
This is accomplished by starting new local Clients within the task that can
interact with the scheduler.
deffunc():fromdistributedimportlocal_clientwithlocal_client()asc2:future=c2.submit(...)c=Client(...)future=c.submit(func)There are a few straightforward use cases for this, like iterative algorithms with stoping criteria, but also many novel use cases including streaming and monitoring systems.
Restart Workers in Redeployable Python Environments
You can now zip up and distribute full Conda environments, and ask dask-workers to restart themselves, live, in that environment. This involves the following:
- Create a conda environment locally (or any redeployable directory including
a
pythonexecutable) - Zip up that environment and use the existing dask.distributed network to copy it to all of the workers
- Shut down all of the workers and restart them within the new environment
This helps users to experiment with different software environments with a much faster turnaround time (typically tens of seconds) than asking IT to install libraries or building and deploying Docker containers (which is also a fine solution). Note that they typical solution of uploading individual python scripts or egg files has been around for a while, see API docs for upload_file
Acknowledgements
Since version 1.12.0 on August 18th the following people have contributed commits to the dask/distributed repository
- Dave Hirschfeld
- dsidi
- Jim Crist
- Joseph Crail
- Loïc Estève
- Martin Durant
- Matthew Rocklin
- Min RK
- Scott Sievert